Tutorial: multi-domain, tests, targets¶
Table of contents¶
- Cross-domain dependencies
- Small tests
- Medium tests
- Large tests
- Using different targets
- Explicit dbt target
- Customizing retries
DAG file: example_advanced_dmp_af_dag.py
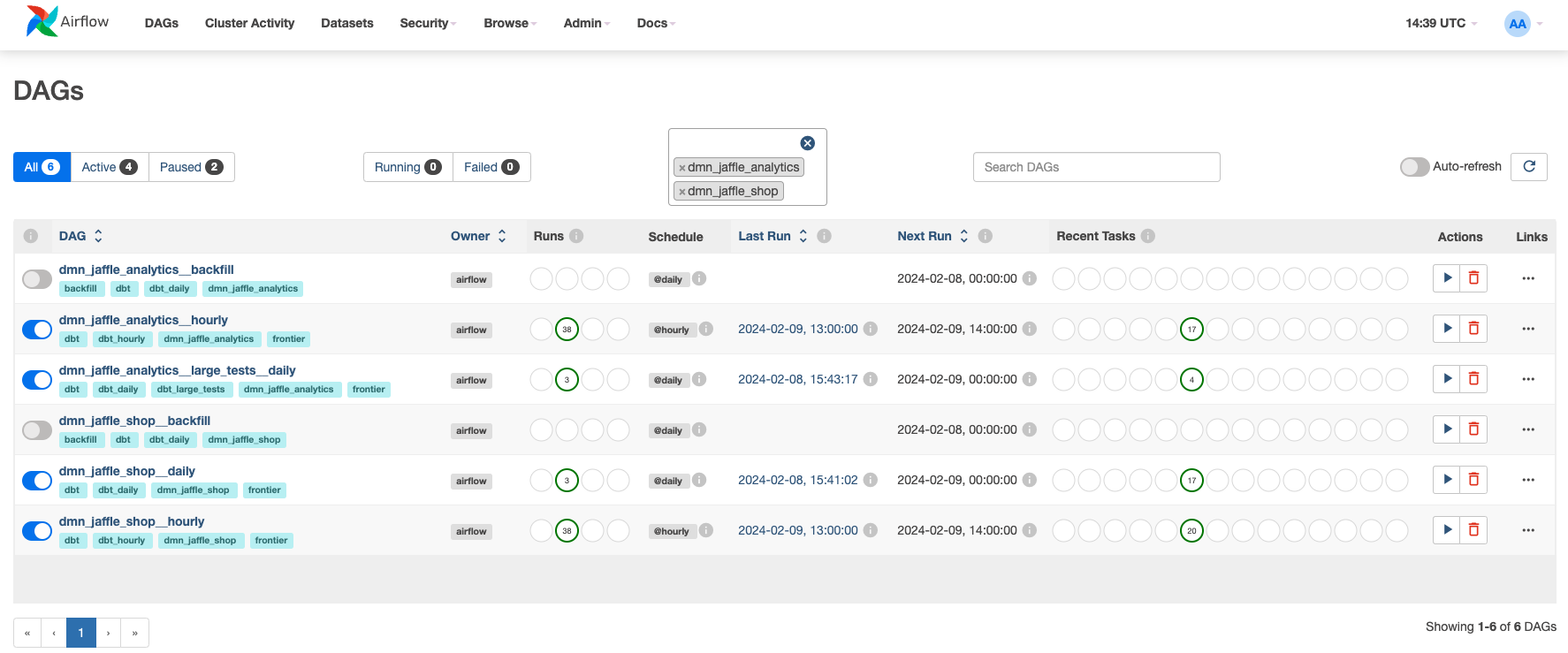
This tutorial will show you how to create a multi-domain project with tests and use different dbt targets.
Essentially, we will create a project that has this structure:
├── etl_service/
│ ├── dbt/
│ │ ├── models/
│ │ │ ├── dmn_jaffle_analytics/
│ │ │ │ ├── ods/ (@hourly scheduling)
│ │ │ │ │ ├── dmn_jaffle_analytics.ods.customers.sql
│ │ │ │ │ ├── dmn_jaffle_analytics.ods.customers.yml
│ │ │ │ │ ├── ... (models from the ods layer)
│ │ │ ├── dmn_jaffle_shop/
│ │ │ │ ├── ods/ (@hourly scheduling)
│ │ │ │ │ ├── dmn_jaffle_shop.ods.customers.sql
│ │ │ │ │ ├── dmn_jaffle_shop.ods.customers.yml
│ │ │ │ │ ├── ... (models from the ods layer)
│ │ │ | ├── staging/ (@daily scheduling)
│ │ │ │ │ ├── dmn_jaffle_shop.staging.customers.sql
│ │ │ │ │ ├── dmn_jaffle_shop.staging.customers.yml
│ │ │ │ │ ├── ... (models from the staging layer)
│ │ ├── seeds/
│ │ │ ├── dmn_jaffle_shop/
│ │ │ │ ├── raw/
│ │ │ │ │ ├── dmn_jaffle_shop.raw.customers.csv
│ │ │ │ │ ├── dmn_jaffle_shop.raw.orders.csv
│ │ │ │ │ ├── ... (seeds from the raw layer)
├── dbt_project.yml
├── profiles.yml
We use one dbt_project.yml file and one profiles.yml file to manage the different etl services. ETL service is a logically separated part of the project that has its own dbt models, seeds, and tests. Each ETL service must be run independently of the others, maybe even in separate Airflow instance.
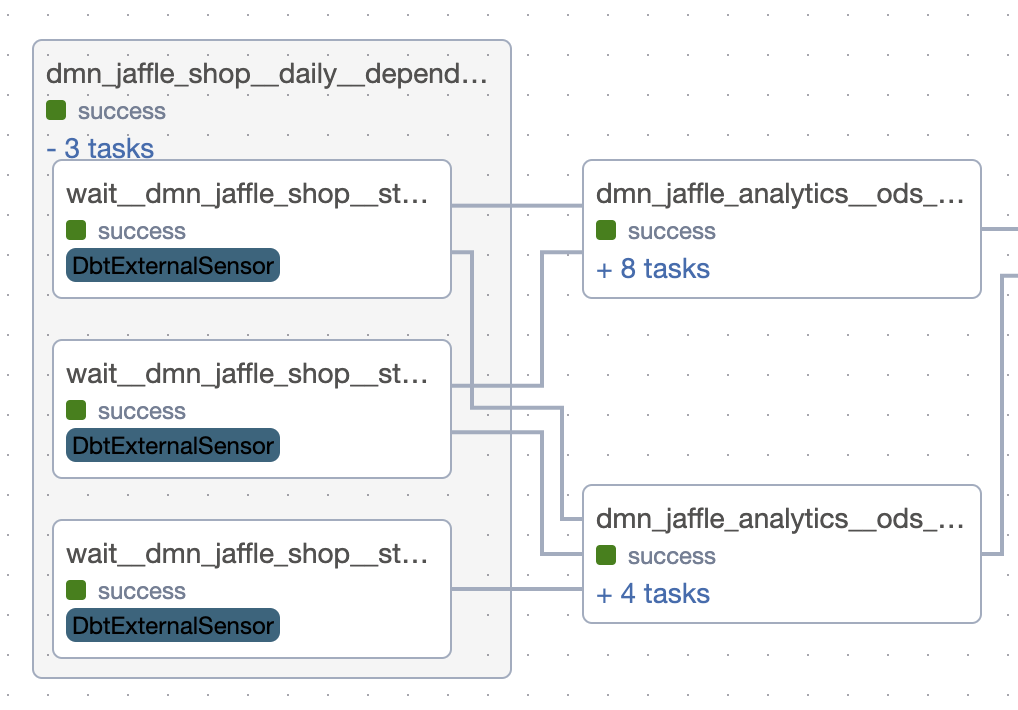
Cross-domain dependencies¶
All models in dmn_jaffle_analytics.ods refer models from dmn_jaffle_shop.ods. This will create for each dependency a group with sensors to start execution of the dependent group only when the upstream models are finished.
Small tests¶
All dbt tests that are not tagged get @small tag. All small tests for one models will be collected in the same task group. They will be run immediately after the models are finished, and if any of them fails, the downstream models won't be executed.
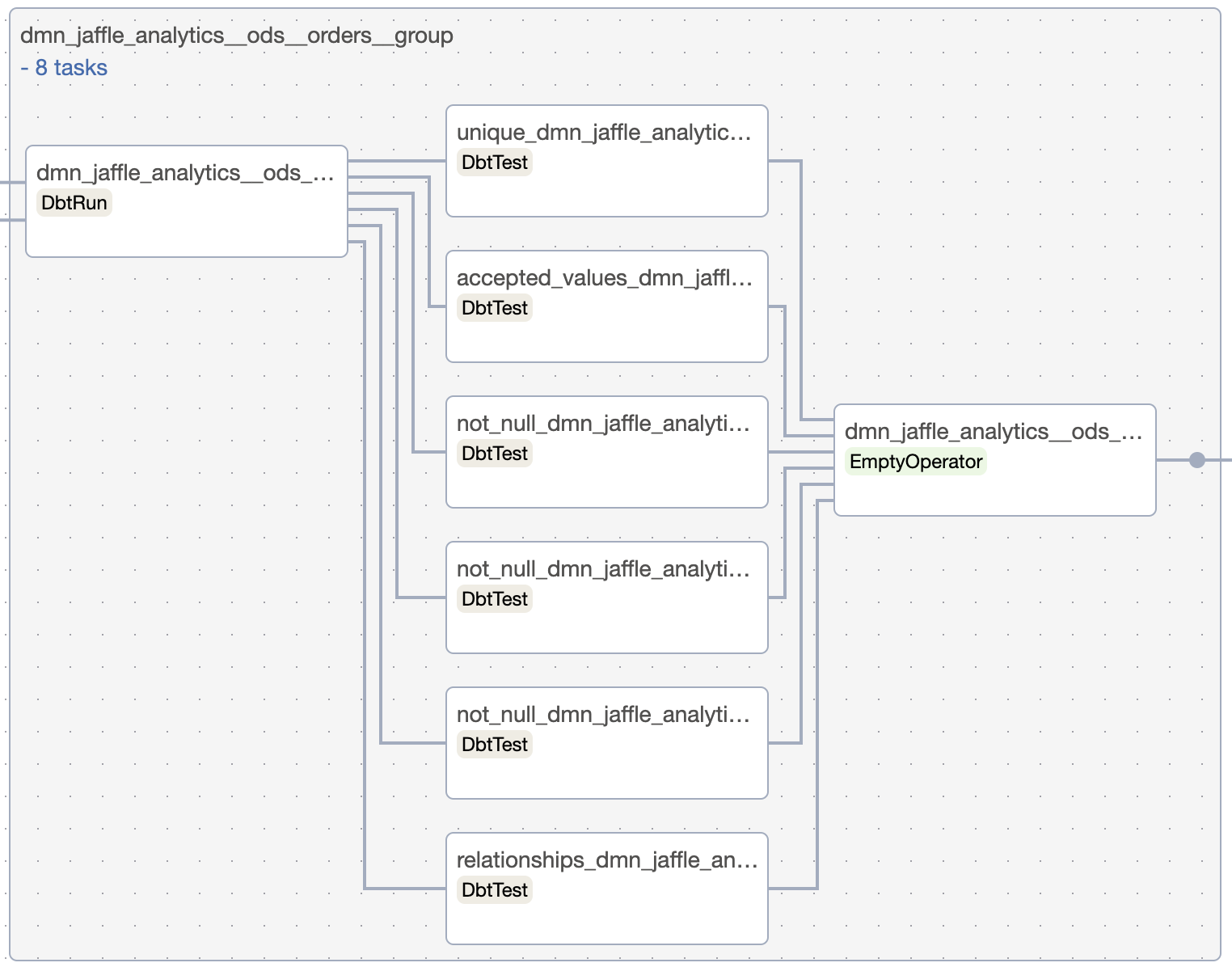
Each test will appear in the separate operator to make all runs atomic.
To handle tasks execution order properly between task groups, all tasks are connected to their downstreams and each task group has endpoint (dummy task) task that is connected to the next task group.
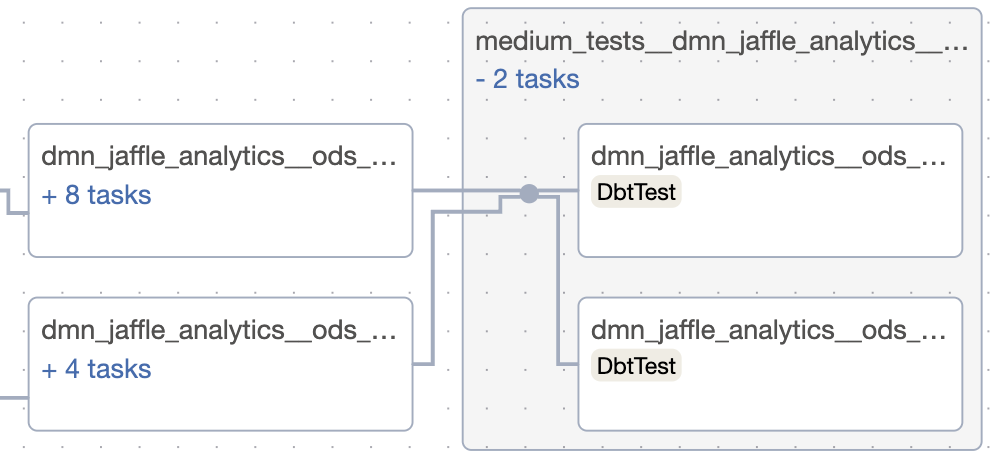
Medium tests¶
Medium tests are designed to be non-blocking for the downstream models and be more time- and resource-consuming. They are run after all models in the DAG.
To set up medium test just add @medium tag to the test.
Medium tests are binding to all DAG's leaves.
Note
Medium tests can only be configured for models that have their own yml file.
Large tests¶
Large tests are designed to be most heavy and time-consuming. They are placed in special DAG for each domain (DAGs are named like @daily scheduling.
Using different targets¶
Because of different payloads, it might be useful to use different targets for different models' and tests' types. Some of them require more resources, some of them are more time-consuming, and some of them are more important.
With dmp-af it's required to set up four targets in dbt_project.yml file for all models and seeds:
models:
sql_cluster: "dev"
daily_sql_cluster: "dev"
py_cluster: "dev"
bf_cluster: "dev"
seeds:
sql_cluster: "dev"
daily_sql_cluster: "dev"
py_cluster: "dev"
bf_cluster: "dev"
and to set up default targets in dmp-af config:
from dmp_af.conf import Config, DbtDefaultTargetsConfig
config = Config(
# ...
dbt_default_targets=DbtDefaultTargetsConfig(
default_target='dev',
default_for_tests_target='dev', # could be undefined, then default_target will be used
),
# ...
)
In this example, all models and seeds are going to be run at dev target. But you can customize it for your needs for each domain and each layer.
How is the target determined?¶
There are a few rules to determine the target for the task:
- If the node is test, then
config.dbt_default_targets.default_for_tests_targettarget is used. - If the node is model:
- If there are no pre-hooks, it's sql model, and scheduling is
@dailyor@weekly, thendaily_sql_clustertarget is used. - Otherwise,
sql_clustertarget is used.
- If there are no pre-hooks, it's sql model, and scheduling is
- Otherwise, use
py_clustertarget.
Explicit dbt target¶
In rare cases, you might want to run a specific model at a specific target. You can do this by setting the dbt_target parameter in the model's config.
Customizing retries¶
Since dmp-af is built from different DAG components (dbt tasks, sensors, etc.), you can customize retries for each component type. To do this, you can specify desired retry policies in the dmp-af config.
By default, there's a default retry policy for all components, but you can override it for each component type individually:
from datetime import timedelta
from dmp_af.conf import Config, RetriesConfig, RetryPolicy
config = Config(
# ...
retries_config=RetriesConfig(
default_retry_policy=RetryPolicy(
retries=1,
retry_delay=timedelta(minutes=5),
retry_exponential_backoff=True,
max_retry_delay=timedelta(minutes=30)
),
dbt_run_retry_policy=RetryPolicy(retries=3),
)
# ...
)
All unspecified policies or policies' parameters will fall back to the default retry policy.
List of Examples¶
- Basic Project: a single domain, small tests, and a single target.
- Dependencies management: how to manage dependencies between models in different domains.
- Manual scheduling: domains with manual scheduling.
- Maintenance and source freshness: how to manage maintenance tasks and source freshness.
- Kubernetes tasks: how to run dbt models in Kubernetes.
- Integration with other tools: how to integrate dmp-af with other tools.
- [Preview] Extras and scripts: available extras and scripts.